1. Organizing teams and platforms for success
We recommend that organizations take an incremental approach to funding and building the teams necessary to establish and continuously improve cATO. We expect that our list of prioritized problems will change over time. Because of this, we can focus on things such as scaling problems once we have achieved desirable outcomes defined by our initial, smaller experiments. To do this we’ve outlined what we believe organizations will need (or at least consider) for (A) Day 1 Team Topologies vs. what they should consider funding for (B) Day 2 Team Topologies, if they achieve success. We also provide an overview of (C) Platform Strategy. This play assumes that your organization already has an established set of enterprise support teams in place (e.g. teams that support SDLC toolsuite, GRC, NSOC, CSOC, etc.), and focuses solely on structuring new teams required to enable cATO.
A) Day 1 Team Topologies
Your Platform Team will enable all of the necessary capabilities required for application teams to safely and securely host, develop and deploy their software onto the platform, leveraging your cATO. This team will also be responsible for providing necessary user docs and either API or CLI interfaces that allow all other teams to consume its services without requiring time from your platform engineers. They will also manage their own authorization, inheritable common control baseline details, day two operational support to dev teams, and ongoing feature development for future application team needs.
Operating as both a customer to the platform, and an enabler of cATO for application development teams, is a Pipelines & Pathways Team. While the number of capabilities being offered may vary, this team is responsible for a centralized service offering of CI/CD pipelines. These pipelines must be reliable, readily available and well maintained for business continuity. They are also responsible for ensuring that the attestation of software changes being shipped onto the platform has been fully vetted through gating criteria built into the pipeline itself. Similar to the platform team, this pipelines & pathways team is also responsible for maintaining inheritable common control baseline details that are used to define how configuration management is enforced. In some cases of net-new application development, it can also be valuable for this team to maintain a repository of starter kits (i.e. hello-world apps) that provide application teams with a baseline set of security and privacy controls that can be considered fully assessed.
We’ve mentioned this in several areas of the playbook already, but you’ll want to fence off some of your budget to reserve a Security Controls Assessor & Privacy Officer Team (if privacy data is applicable for your situation). Following the ratio guidance we outlined here, the good news is that during your start up phase of cATO, you should really only need one of each for this team.
B) Day 2 Team Topologies
At some point in this journey, it will no longer be sustainable for Day 1 Team Topology teams to help handhold every product team through onboarding and guidance on the path to production, nor will they have the time to consistently interview and perform user research with every product team leveraging your cATO. It’s also safe to assume that as you begin to increase adoption of the platform and cATO, that the needs of application teams will be increasing beyond your ability to deliver all at once. This is where introducing a Customer Success Team can really come in handy. When done right, this team can properly segment and offer various services to application teams based upon specific maturity demographics. This also includes breaking down helpful resources that can be consumed, on-demand, during different phases of the path to production. Equipped with the bandwidth to interview and experience what your customers are experiencing, makes it easier to relay both optimizations and opportunities for new ways to engage with users using the products and services being offered. Therefore, the most important responsibility for this team is creatively gaining insights for improvement, serving the needs of application teams on their path to production, and contributing into any resources that support those activities.
Another scaling problem that we always witness, is the desire to enable a seamless, end-to-end, customer experience - from onboarding to achieving ATO and continuous delivery. The last thing you want is to have every platform or services team, marketing or enabling consumption of their services in a disparate and disjointed way. This will degrade user advocacy and adoption, thus killing your business cases for scale. This is where we recommend introducing a Marketplace Team. This can be as simple as centralizing and standarding your marketing strategy, materials and having a single user doc that explains how to consume and provision all of the various capabilities and services being offered for your path to production. It can also be as elegant as providing a web application experience that guides application teams through the provisioning, configuring and management of resources they need to ship code (e.g. accounts, SDLC tools, platform resources, governance, requirements and compliance, etc), in an on-demand and continuous way. Typically, this team will focus on making it easy to consume, swap and retire the resources they require for developing and shipping code onto your platform. As your platform, pipeline and cATO capabilities begin to mature, and a desire for Customer Relationship Management starts to increase, this team may also start to integrate with other systems to share and consume data for unique business needs.
While each product team should always be investing in their own ability to capture data and metrics to help drive decision making processes, the volume and complexity of your data will require a Data & Analytics Team. At a minimum we believe this team will be responsible for defining standard data solutions and processes for creating, consuming, storing, processing and visualizing data in reports or dashboard, for all teams to leverage.
C) Platform Strategy
Don’t build when you can buy, don’t buy when you can rent.
We have a forthcoming video on this topic. In the meantime, we want to explain why building your own platform services, including those associated with implementation security and privacy risk management, will likely keep you from ever having a well-paved path to production.
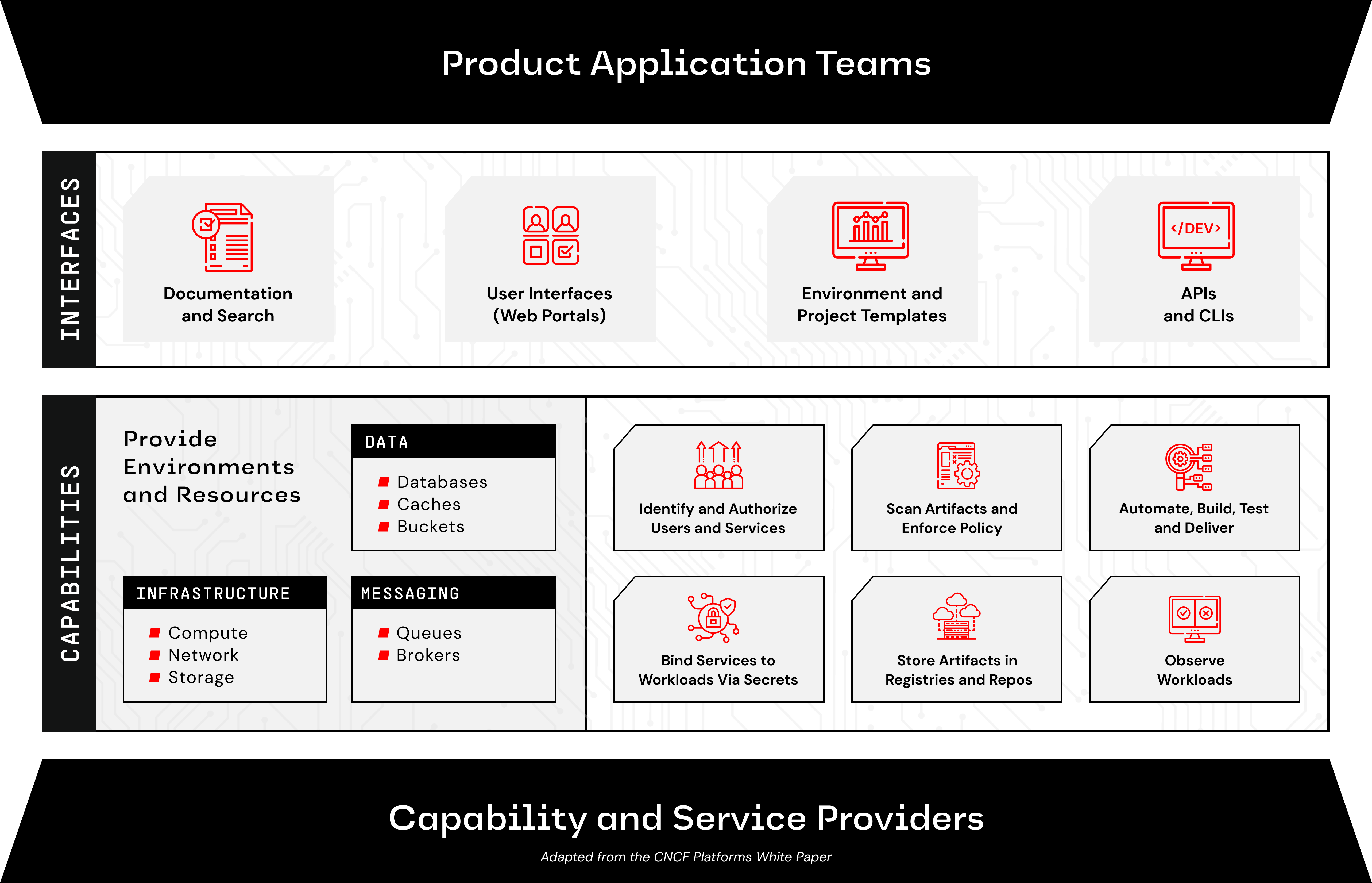
According to the CNCF Platforms White Paper, “here are capability domains to consider when building platforms for cloud-native computing:
- Web portals for observing and provisioning products and capabilities
- APIs (and CLIs) for automatically provisioning products and capabilities
- "Golden path" templates and docs enabling optimal use of capabilities in products
- Automation for building and testing services and products
- Automation for delivering and verifying services and products
- Development environments such as hosted IDEs and remote connection tools
- Observability for services and products using instrumentation and dashboards, including observation of functionality, performance and costs
- Infrastructure services including compute runtimes, programmable networks, and block and volume storage
- Data services including databases, caches, and object stores
- Messaging and event services including brokers, queues, and event fabrics
- Identity and secret management services such as service and user identity and authorization, certificate and key issuance, and static secret storage
- Security services including static analysis of code and artifacts, runtime analysis, and policy enforcement
- Artifact storage including storage of container image and language-specific packages, custom binaries and libraries, and source code
Here is what that looks like:
That is a lot of capability. Developing, deploying, operating, and maintaining all that capability would realistically take more resources (people and money) than you want to spend for what is below the mission value line. Here is a very conservative look at solely the labor costs for each area:

What’s the value in that? Since we are part of the federal acquisition system, I really want to emphasize that cost, schedule, and performance are one side of a value equation. Value equals performance divided by the product of schedule and cost. It’s important because no matter how much you minimize cost and schedule, if performance is low, value will be low. It’s also worth noting that performance isn’t measured against a specification, but against what the mission and the user really needed–in this case a platform that enables applications to continuously deliver with reduced cognitive load.
I’m going to expand the variables using Alex Hormozi’s version where performance is actually the dream outcome multiplied by the likelihood of achievement and the cost is both effort and sacrifice, not just money. We all understand the dream outcome: we want a mature platform that includes all the 13 capability areas. According to the CNCF Platforms White Paper, it needs to have: High User satisfaction and productivity, high organizational efficiency, and high product and feature delivery.
But how likely are we to achieve that? Can we get the talent? Will they be productive? Will your acquisitions strategy and contract rates get approved? Will you get the right contractors? The likelihood of achievement is low… off to a bad start. The time delay is high… I already said that’s a five year journey minimum. Effort and sacrifice are incredibly high… we haven’t even calculated the total cost of ownership and we already know it will cost a lot of people/FTEs and is high effort on the government’s part. Small numerator, really big denominator… ladies and gentlemen, DIY platform is a low value endeavor for you until this equation changes.
Here is a buy example, where many FTEs are avoided by buying platform licenses, conservatively reducing total cost by 50% while improving likelihood, drastically lowering TTV, and lowering effort and stress:
